Existing text-to-image (T2I) diffusion models usually struggle in interpreting complex prompts, especially those with quantity, object-attribute binding, and multi-subject descriptions. In this work, we introduce a semantic panel as the middleware in decoding texts to images, supporting the generator to better follow instructions. The panel is obtained through arranging the visual concepts parsed from the input text by the aid of large language models, and then injected into the denoising network as a detailed control signal to complement the text condition. To facilitate text-to-panel learning, we come up with a carefully designed semantic formatting protocol, accompanied by a fully-automatic data preparation pipeline. Thanks to such a design, our approach, which we call Ranni, manages to enhance a pre-trained T2I generator regarding its textual controllability. More importantly, the introduction of the generative middleware brings a more convenient form of interaction (i.e., directly adjusting the elements in the panel or using language instructions) and further allows users to finely customize their generation, based on which we develop a practical system and showcase its potential in continuous generation and chatting-based editing.
Samples generated by Ranni with different interaction manners, including (a) direct generation with accurate prompt following, (b) continuous generation with progressive refinement, and (c) chatting-based generation with text instructions.
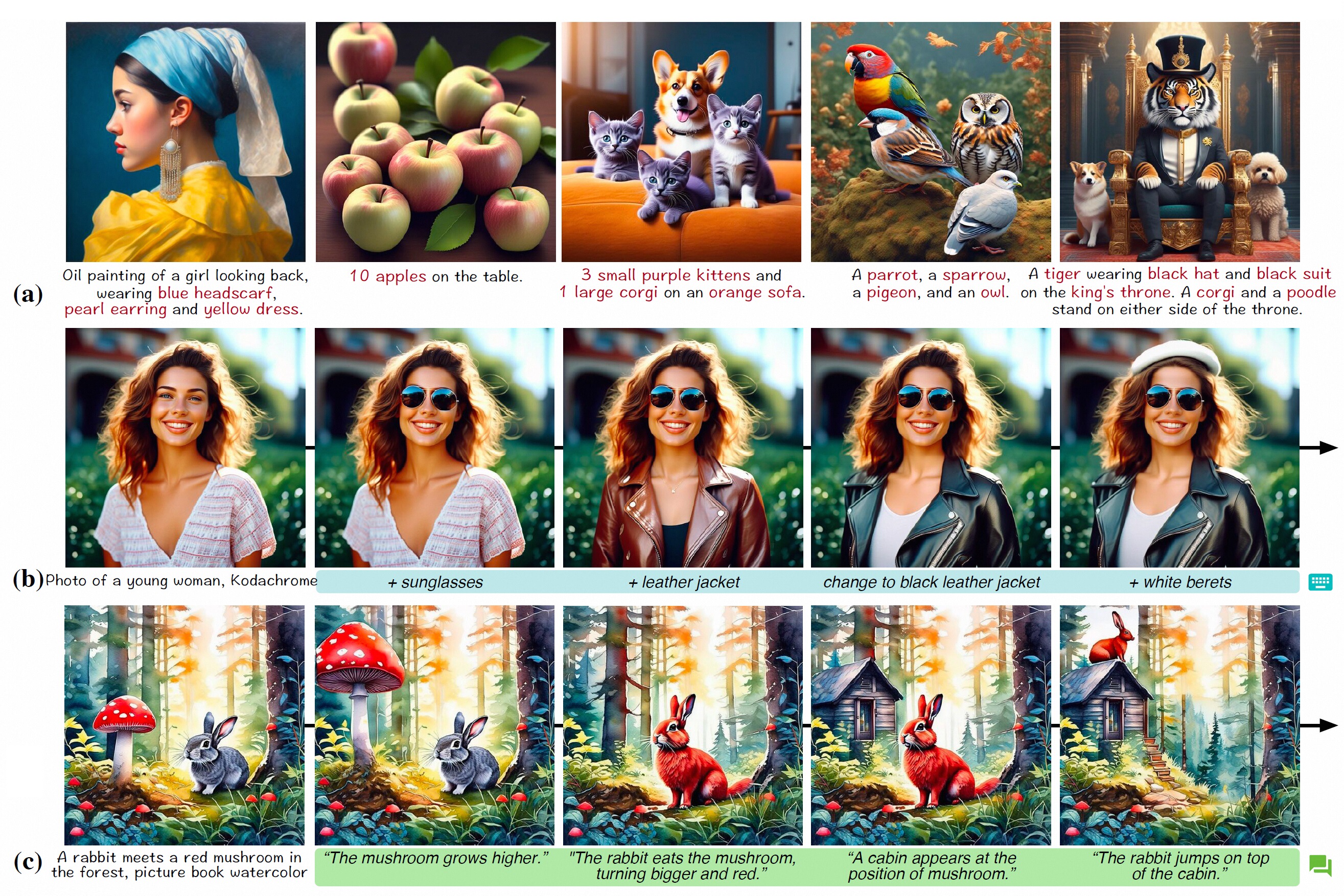
Samples generated by Ranni on quantity-awareness prompts.

Samples generated by Ranni on spatial relationship prompts.

Samples generated by Ranni on attribute binding prompts, including the (a) color binding and (b) texture binding. For clear comparison, the random seed is fixed to preserve the spatial arrangement in one row.

The editing results and corresponding panel update for each unit operation.

Examples of color editing by Ranni.

Examples of shape editing by Ranni. The blue arrows indicate the direction of keypoints moving.


